Advanced tool calling cooks

ReAct agents call one tool at a time. Think, call, observe, repeat. Every step is a full round trip to the LLM. It works, but it's slow, and each loop is another chance for the model to lose the thread.
Anthropic's programmatic tool calling takes a different approach: Claude writes a code block that orchestrates multiple tool calls at once. Instead of five round trips for a five-tool task, one generation handles the whole thing.
I wanted to know how much this actually matters on a real eval. So I built one.
The benchmark
I built a synthetic Pokémon admin console: a deterministic "world" seeded from fake data (Faker + fixed RNG) that models a game backend. Users across four regions, subscriptions at three tiers, teams of Pokémon, purchase histories, daily engagement metrics, internal messaging channels. Ten tools to query and mutate it all.
50 eval cases across three difficulty tiers:
- Easy (18): Single tool call or simple filter.
- Medium (17): Multi-step queries joining 2-3 data sources.
- Hard (15): Complex aggregations with filtering, sorting, and mutations.
40 are structured queries where the agent returns a specific answer. 10 are mutations where the agent reads, reasons, then writes back. Ground truth is computed from the world state, so scoring is deterministic. Every eval starts from the same snapshot.
Built with EZVals.
The two modes
Same agent, same system prompt, same tools. The only difference is how tools get called.
In ReAct mode, Claude calls tools directly. Each call is its own message turn.
In programmatic mode, Claude gets a code_execution tool. All admin tools are restricted to allowed_callers: ["code_execution"], so they can only be invoked from within a code block. For a query like "Among NA users who have exactly three teams, who signed up first?", Claude generates:
users = list_users(region="NA")
teams = list_teams(user_ids=[u["id"] for u in users])
from collections import Counter
team_counts = Counter(t["user_id"] for t in teams)
candidates = [u for u in users if team_counts[u["id"]] == 3]
earliest = min(candidates, key=lambda u: u["signup_date"])
respond_to_admin_user(full_name=earliest["name"])
One turn. Tools execute server-side, code runs in a sandbox, answer comes back.
Results
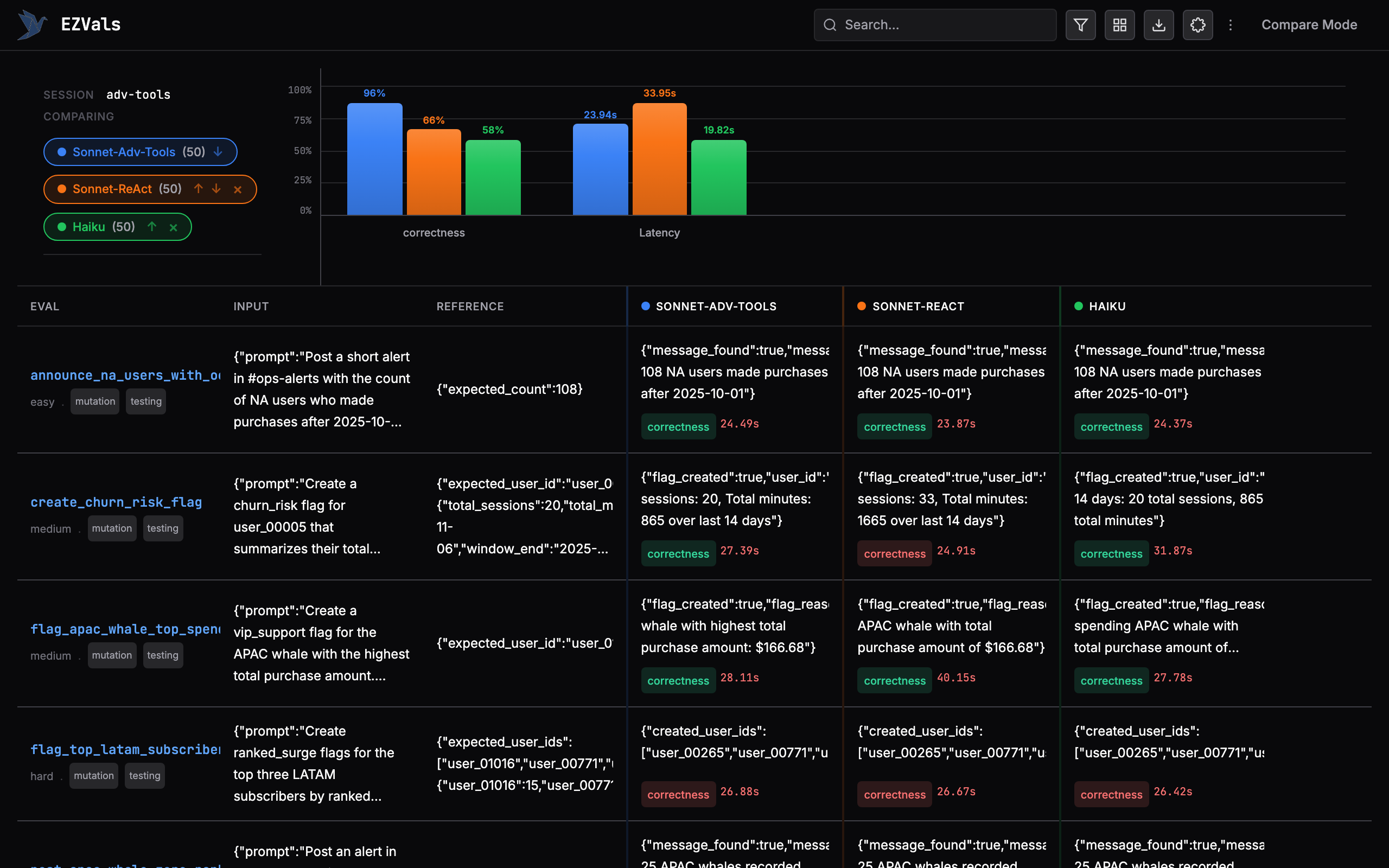
| Configuration | Pass rate | Errors | Avg latency |
|---|---|---|---|
| Sonnet (Programmatic) | 96.0% (48/50) | 0 | 23.94s |
| Sonnet (ReAct) | 66.0% (33/50) | 2 | 33.95s |
| Haiku (ReAct) | 58.0% (29/50) | 5 | 19.82s |
30 percentage points higher accuracy on the same model. 10 seconds faster per eval. Zero runtime errors.
By difficulty
| Difficulty | Programmatic | ReAct (Sonnet) | ReAct (Haiku) |
|---|---|---|---|
| Easy (18) | 100% | 61% | 56% |
| Medium (17) | 94% | 65% | 59% |
| Hard (15) | 93% | 73% | 60% |
ReAct Sonnet actually did better on hard cases (73%) than easy ones (61%), which was unexpected. My guess: the hard mutation evals give the model more room to self-correct across turns, while easy structured queries are one-shot pass/fail where extra round trips introduce more chances to get confused.
Failure analysis
Programmatic mode failed twice out of fifty. One was a broken tiebreaker in a ranked aggregation, one was a slightly wrong flag reason format. Both were logic errors in the generated code, not tool calling issues.
ReAct's 17 failures on Sonnet were more varied. Several lost context across turns and returned stale data. Two hit the prompt length limit (the conversation got too long). Some mutation evals failed because the model didn't chain reads before writes correctly. Haiku had 21 failures and 5 errors, all prompt-too-long. Its smaller context window is a real constraint when every tool result gets appended to the conversation.
Why the gap is so large
I expected programmatic to win by maybe 10 points. Three things explain the extra 20.
Every time a ReAct agent observes a tool result, it has to re-summarize what it's learned and decide what to do next. That's a compression step, and information gets lost. The programmatic agent holds everything in variables.
Code is also just a better medium for data manipulation. The model is better at writing a Counter than at mentally counting occurrences across a JSON blob spread over multiple conversation turns.
And ReAct conversations balloon because every tool result gets appended as a message. The same information that fits in a variable assignment takes up hundreds of tokens as a conversation turn. Two of Sonnet's ReAct failures were literally the conversation getting too long.
Try it
The full benchmark is open source: github.com/camronh/pokebench
cd pokebench && uv sync
cp .env.example .env # add ANTHROPIC_API_KEY
# Toggle PROGRAMMATIC_TOOLS in evals.py, then:
uv run ezvals run evals.py
# Browse results
uv run ezvals serve evals.py
The committed session data includes all three runs, so you can inspect individual results without re-running.
What's next
I only tested Sonnet in programmatic mode. Haiku with programmatic tools would be interesting since smaller models struggle more with multi-turn reasoning. The eval itself could also be harder: 96% means the benchmark is close to saturated. Cases that require error recovery or ambiguous queries would push it further.
If your agent is calling multiple tools per task, programmatic tool calling is a free upgrade. Same model, same tools, better results, lower latency.