Evals 102: Let Your Agent Do the Hard Parts

I gave a follow-up talk at the LangChain meetup on more advanced eval patterns. This blog covers the main ideas.
A few months ago I gave a talk on the basics of agent evaluation. The gist: stop copy-pasting test prompts like a caveman. Build datasets. Run evaluators. Measure things. That talk covered tests versus evals, black-boxing your agent's output, and a pattern I call "stress testing": find an issue, build a small dataset around it, iterate until it's fixed.
This is the sequel. I'm assuming you're using coding agents (Claude Code, Cursor, Codex, whatever). If you're not, the ideas still apply, but the real unlock is what happens when your coding agent becomes part of the eval process itself.
The meta-evaluator, briefly
I've written about this before, so I'll keep this short.
Your coding agent can act as an ad-hoc judge. It runs your production agent, looks at the outputs, decides if they're good, changes the prompts, re-runs. All in one session, maintaining context about the original problem.
Building formal evaluators is painful. Create a dataset, write a judge prompt, align the judge to your preferences, run the suite, review results, correct the judge where it disagrees with you, and then start fixing your agent. A lot of steps for a 20-minute problem.
The coding agent collapses that. You describe the problem, it figures out the rest.
flowchart LR
A["You: describe problem"] --> B["Agent: reproduce"]
B --> C["Agent: evaluate"]
C --> D["Agent: fix"]
D --> E["Agent: verify"]What I want to focus on is what this looks like in practice, and how it changes the way you think about offline evaluation.
Offline evals: old way vs. new way
Offline evaluation is when you test your agent locally, outside production. Maybe you saw something in prod that looked off, or maybe you're building a new feature. Either way, you're running experiments before shipping.
The old way:
- Find an issue (or anticipate one)
- Try a bunch of queries to reproduce it
- Identify which queries trigger the problem and which don't
- Put those into a dataset
- Build an evaluator
- Build a judge
- Run the evaluation
- Review results and correct the judge where it's wrong
- Re-run until the judge is trustworthy
- Now start iterating on your agent
Ten steps before you've started fixing the actual problem. Steps 5 through 9 are where most people give up, and honestly, I don't blame them. Aligning a judge is its own science. Building good datasets is tedious. And you still have to do the engineering work after all that.
The new way, with a coding agent:
- Find an issue
- Tell your agent about it
- Wait
That's only slightly exaggerated. If your agent is set up correctly (more on that below), it reproduces the issue, builds a small dataset of triggers, writes evaluators, iterates on the prompts, and verifies the fix. Steps 2 through 10, handled. All you do is describe the problem and review the result.
When formal judges fall short
Some problems are just hard to evaluate with a traditional judge, even a well-aligned one.
Take the classic example: "The agent is using too many emojis."
A formal eval would need a judge that scores emoji appropriateness. But the judge runs in isolation. It sees the output and maybe a reference. It doesn't know how many emojis there were before. You can't say "we want less emojis" because "less" is relative, and the judge has no baseline.
You could encode that context into the judge prompt, but now you're spending an hour on alignment for a vibes problem. And if you later decide zero emojis is too aggressive, you re-align the judge and re-run everything.
With the meta-evaluator, you say: "We're using too many emojis." The agent runs a few examples, tweaks the prompt, re-runs, compares. It knows what "less" means because it sees the before and after. Tell it "that's too few, bring some back," and it adjusts without rebuilding anything.
Not every issue needs a formal eval
The emoji example is trivial, but the principle applies broadly. Anything subjective, anything where judgment requires context that's hard to serialize into a judge prompt, anything where you'd rather look at the outputs and say "yeah, that's better" ... the meta-evaluator is faster and often more accurate.
Formal evals aren't dead. Clear right/wrong answers? Build a proper eval. But for the long tail of qualitative issues, the meta-evaluator gets you 80% of the way with 10% of the effort.
Wire your agent to production
This pattern gets much better when your agent has direct access to production data.
We built a LangSmith skill for our coding agent. When something goes wrong in production, I paste the trace URL into the agent. It pulls the trace, inspects the retrieved documents, reads the full conversation. Then it reproduces the issue locally because I gave it the ability to invoke our production agent.
The pipeline:
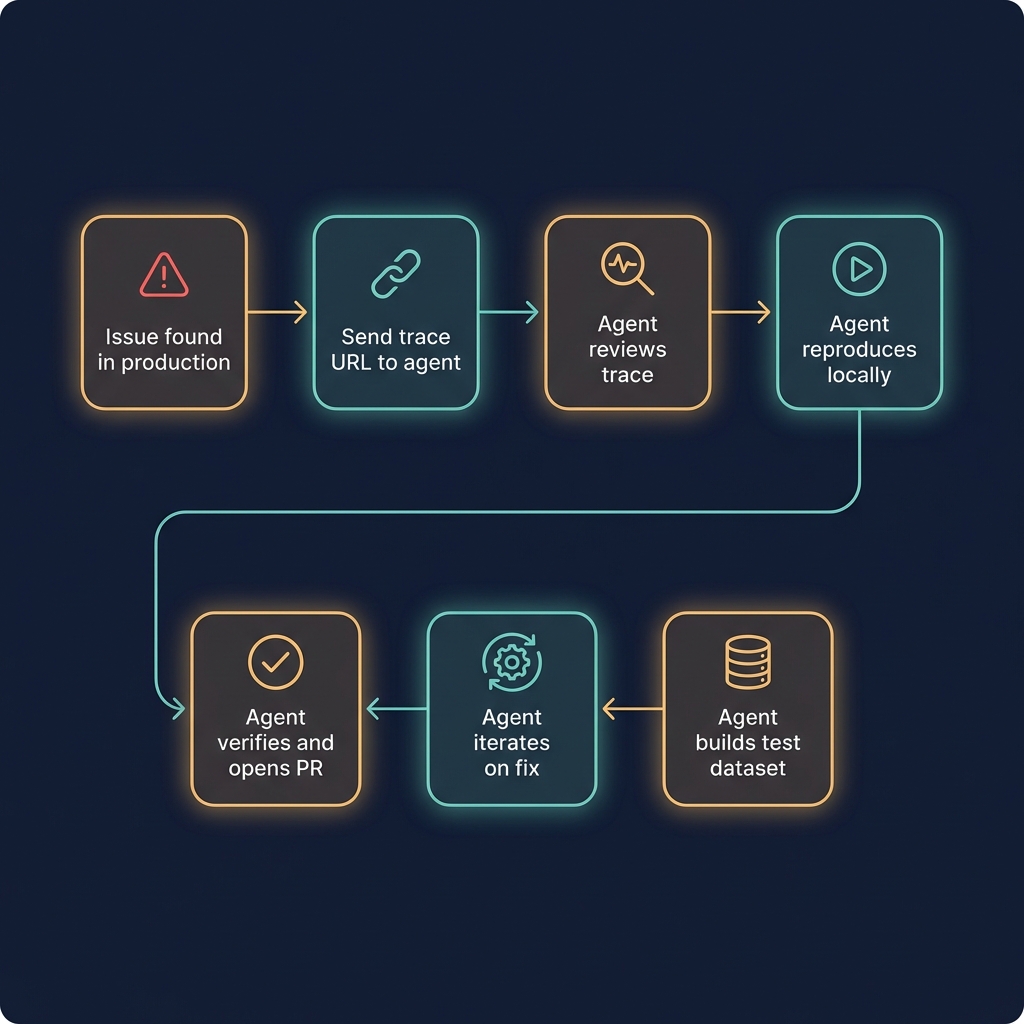
Steps C through H happen without me. I paste a URL, go do something else, and come back to a pull request. That's the dream, anyway, and it works more often than you'd expect.
The key enablers:
1. Your agent needs to run your production agent. If you can't run your agent locally with a single command, fix that first. Feedback loops are non-negotiable.
2. Your agent needs access to production traces. LangSmith integration, a log parser, a JSON export. The agent needs to see what actually happened.
3. Describe problems clearly. "Something's off" is harder to work with than "Pro plan users are getting answers that reference free tier docs." Be specific. But even vague problems work if the agent has good observability.
Stop building golden datasets
I've written about this at length. Short version: don't build a single growing benchmark that tracks your agent's quality over time.
Golden datasets sound appealing. You see SWE-bench and think "I want that for my product." But those benchmarks work because the dataset is static and only the model changes. You're changing everything simultaneously. You'll saturate any benchmark you build within weeks.
When you saturate, the instinct is to make the dataset harder. But if your users aren't asking harder questions, your dataset stops being representative. You're optimizing for a distribution that doesn't exist.
And it compounds from there: ground truths go stale, SMEs disagree on edge cases, new features make scoring ambiguous. Does a new capability raise the score because the agent can do more, or lower it because the dataset got broader? It's a maintenance nightmare that never ends.
So what do you do instead?
Capability datasets and regression datasets
Anthropic published a good writeup on this that formalizes something I'd been doing. Split your evaluation into two buckets: capability datasets you're actively working against, and regression datasets you're maintaining.
The cycle:
flowchart TD
A["Find an issue or build a new capability"] --> B["Build a small capability dataset<br/>~10-50 examples"]
B --> C["Iterate until you're near saturation"]
C --> D["Ship the fix/feature"]
D --> E["Move the dataset to the<br/>regression bucket"]
E --> F["Take the next issue"]
F --> A
E --> G["Regression bucket grows over time"]
G --> H["Run regression sweeps<br/>after major changes"]
H --> I["Expect scores to stay<br/>the same, not go up"]Say you're working on answer correctness for a specific topic. You build a dataset of 50 questions. You're scoring 20%. You spend a week iterating: error analysis, prompt changes, retrieval fixes, maybe a tool update. Now you're at 90%. Saturated.
At this point, re-running that dataset won't teach you anything new. You've extracted all the information those 50 questions have to offer.
Move it to regression. It becomes a check you run after big changes (model swaps, architecture refactors, prompt rewrites) to make sure nothing broke. You're not hoping the score goes up. You're hoping it stays the same.
Then take the next issue. Build another small capability dataset. Iterate to saturation. Move to regression. Repeat.
Over time, the regression bucket grows into something useful: targeted datasets, each built around a specific capability or failure mode you've already solved. Swap models or make a big change, run the suite, see what broke and what held.
The Swiss army knife
After six months, you might have 10-15 small datasets in regression, each covering a different aspect of your agent. More useful than any golden dataset, because each piece tests something specific with aligned judges and relevant examples. None of them are stale, because you only added them after confirming they worked.
Don't try to desaturate
When you saturate a dataset, the instinct is to make it harder. Don't.
If your users ask questions at difficulty 3 (arbitrary scale) and you saturate at difficulty 3, the temptation is to build a dataset at difficulty 5. But users aren't asking difficulty 5 questions. Your new dataset doesn't reflect what the agent needs to handle. You've traded relevance for a number going up in a slide deck.
Switch the question. Don't ask "how well does the agent handle this topic?" (you already know: 90%). Ask "has the agent regressed after my recent changes?" The question changed, not the data.
Then go find a different capability to evaluate. Something the agent is actually bad at right now. That's where the new information is.
Putting it all together
If I had to summarize this in one sentence: coding agents turn evaluation from a project into a conversation.
The practical checklist:
- Give your coding agent the ability to run your production agent. Step zero.
- Give it access to production traces. Paste URLs, export logs, whatever works.
- Use the meta-evaluator for subjective issues. Not everything needs a formal judge.
- Build small capability datasets for active work. 10 to 50 examples per issue.
- Move saturated datasets to regression. Don't try to keep climbing.
- Run regression sweeps after major changes. Expect maintenance, not improvement.
- Never desaturate by making harder questions. Switch the question instead.
The hard part of evals was never the concept. It was always the execution: building datasets, aligning judges, maintaining stability, doing the analysis. Coding agents absorb most of that now. Your job is describing what you want and reviewing what you get. And that's a much better use of your time.
Related posts:
- AI Agent Testing: Stop Caveman Testing and Use Evals - The 101 talk
- The Meta-Evaluator: Your Coding Agent as an Eval Layer - Deep dive on the meta-evaluator pattern
- Golden Datasets Are Dead - Why the benchmark approach doesn't work
- My Bull Case for Prompt Automation - Why automated prompt iteration is the future